mirror of
https://github.com/sml2h3/ddddocr.git
synced 2025-05-01 15:20:09 +08:00
将老模型合并到代码中
This commit is contained in:
parent
0cea617ff4
commit
cc3351e026
@ -1,2 +1,3 @@
|
||||
recursive-include ddddocr common.onnx
|
||||
recursive-include ddddocr common_old.onnx
|
||||
recursive-include ddddocr common_det.onnx
|
||||
182
README.md
182
README.md
@ -2,14 +2,124 @@
|
||||
|
||||
# 带带弟弟OCR通用验证码识别SDK免费开源版
|
||||
|
||||
# 2021/12/24重大更新,ddddocr现在支持通用目标检测啦
|
||||
# 今天ddddocr又更新啦!
|
||||
当前版本为1.3.1
|
||||
|
||||
想必很多做验证码的新手,一定头疼碰到点选类型的图像,做样本费时费力,神经网络不会写,训练设备太昂贵,模型效果又不好。
|
||||
|
||||
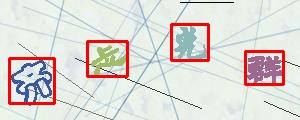
市场上常见的点选类验证码图片如下图所示
|
||||
|
||||
|
||||
## 交流群(找对象,在苏州,dd群主)
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
## 环境要求
|
||||

|
||||
|
||||

|
||||
|
||||
那么今天,他来了,ddddocr带着重磅更新大摇大摆的走来了。
|
||||
# 简介
|
||||
ddddocr是由sml2h3开发的专为验证码厂商进行对自家新版本验证码难易强度进行验证的一个python库,其由作者与kerlomz共同合作完成,通过大批量生成随机数据后进行深度网络训练,本身并非针对任何一家验证码厂商而制作,本库使用效果完全靠玄学,可能可以识别,可能不能识别。
|
||||
|
||||
ddddocr奉行着开箱即用、最简依赖的理念,尽量减少用户的配置和使用成本,希望给每一位测试者带来舒适的体验
|
||||
|
||||
项目地址: [点我传送](https://github.com/sml2h3/ddddocr)
|
||||
|
||||
# 更新说明
|
||||
|
||||
本次更新其实分为两部分,其中有一部分是在1.2.0版本就已经更新了,但是在这里还是有必要提一下的。
|
||||
|
||||
## 第一部分 OCR识别部分
|
||||
|
||||
在1.2.0开始,ddddocr的识别部分进行了一次beta更新,主要更新在于网络结构主体的升级,其训练数据并没有发生过多的改变,所以理论上在识别结果上,原先可能识别效果的很好的图形在1.2.0上有一小部分概率会有一定程度的下降,也有可能原本识别不好的图形在1.2.0之后效果却变得特别好。
|
||||
测试代码:
|
||||
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
|
||||
ocr = ddddocr.DdddOcr()
|
||||
|
||||
with open("test.jpg", 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
res = ocr.classification(image)
|
||||
print(res)
|
||||
```
|
||||
由于事实上确实在一些图片上老版本的模型识别效果比新模型好,特地这次更新把老模型也加入进去了,通过在初始化ddddocr的时候使用old参数即可快速切换老模型
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
|
||||
ocr = ddddocr.DdddOcr(old=True)
|
||||
|
||||
with open("test.jpg", 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
res = ocr.classification(image)
|
||||
print(res)
|
||||
```
|
||||
|
||||
OCR部分应该已经有很多人做了测试,在这里就放一部分网友的测试图片。
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||
|
||||

|
||||

|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
等等更多图片等你测试哟~
|
||||
|
||||
## 第二部分 目标检测部分
|
||||
在本次1.3.0的更新中,目标检测部分隆重登场!
|
||||
目标检测部分同样也是由大量随机合成数据训练而成,对于现在已有的点选验证码图片或者未知的验证码图片都有可能具备一定的识别能力,适用于文字点选和图标点选。
|
||||
简单来说,对于点选类的验证码,可以快速的检测出图片上的文字或者图标。
|
||||
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
import cv2
|
||||
|
||||
det = ddddocr.DdddOcr(det=True)
|
||||
|
||||
with open("test.jpg", 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
poses = det.detection(image)
|
||||
print(poses)
|
||||
|
||||
im = cv2.imread("test.jpg")
|
||||
|
||||
for box in poses:
|
||||
x1, y1, x2, y2 = box
|
||||
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
|
||||
|
||||
cv2.imwrite("result.jpg", im)
|
||||
|
||||
```
|
||||
|
||||
举些例子:
|
||||
|
||||
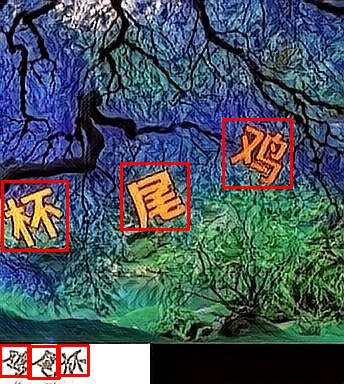
|
||||

|
||||
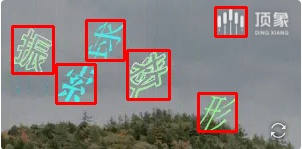
|
||||

|
||||

|
||||
|
||||

|
||||
|
||||
以上只是目前我能找到的点选验证码图片,做了一个简单的测试。
|
||||
|
||||
# 安装
|
||||
|
||||
## 环境支持
|
||||
|
||||
`python <= 3.9`
|
||||
|
||||
@ -17,69 +127,15 @@
|
||||
|
||||
暂时不支持Macbook M1(X),M1(X)用户需要自己编译onnxruntime才可以使用
|
||||
|
||||
## 调用方法
|
||||
## 安装命令
|
||||
|
||||
`pip install ddddocr`
|
||||
|
||||
### 1、文字识别模式
|
||||
以上命令将自动安装符合自己电脑环境的最新ddddocr
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
ocr = ddddocr.DdddOcr()
|
||||
with open('test.png', 'rb') as f:
|
||||
img_bytes = f.read()
|
||||
res = ocr.classification(img_bytes=img_bytes)
|
||||
print(res)
|
||||
```
|
||||
或者传入图片 base64 编码值(不包含图片头)
|
||||
```python
|
||||
import ddddocr
|
||||
ocr = ddddocr.DdddOcr()
|
||||
img_base64 = 'img_base64' # 示例
|
||||
res = ocr.classification(img_base64=img_base64)
|
||||
print(res)
|
||||
```
|
||||
# 交流群 (加我好友拉你进群)
|
||||
|
||||
### 2、目标检测模式
|
||||
```python
|
||||
import ddddocr
|
||||
det = ddddocr.DdddOcr(det=True)
|
||||

|
||||
|
||||
with open('test.jpg', 'rb') as f:
|
||||
img_bytes = f.read()
|
||||
|
||||
res = det.detection(img_bytes)
|
||||
print(res)
|
||||
```
|
||||
|
||||
### 3、参数说明
|
||||
|
||||
`DdddOcr 接受三个参数`
|
||||
|
||||
| 参数名 | 默认值 | 说明 |
|
||||
| ---- | ---- | ---- |
|
||||
| det | False | Bool 默认为识别文字模式,为True则开启目标检测模式 |
|
||||
| use_gpu | False | Bool 是否使用gpu进行推理,如果该值为False则device_id不生效 |
|
||||
| device_id | 0 | int cuda设备号,目前仅支持单张显卡 |
|
||||
|
||||
`classification`
|
||||
|
||||
必须det参数为False后才可使用
|
||||
|
||||
| 参数名 | 默认值 | 说明 |
|
||||
| ---- | ---- | ---- |
|
||||
| img_bytes | None | bytes 图片的bytes格式 |
|
||||
| img_base64 | None | 图片的 base64 编码值(不包含图片头) |
|
||||
|
||||
`detection`
|
||||
|
||||
必须det参数为False后才可使用
|
||||
|
||||
| 参数名 | 默认值 | 说明 |
|
||||
| ---- | ---- | ---- |
|
||||
| img_bytes | None | bytes 图片的bytes格式 |
|
||||
| img_base64 | None | 图片的 base64 编码值(不包含图片头) |
|
||||
|
||||
> 说明,当 `img_bytes` 和 `img_base64` 都存在时,优先使用 `img_bytes`
|
||||
|
||||
> 如果使用GPU,需要自行安装cuda和cudnn,并在安装完ddddocr时执行 <br>`pip uninstall onnxrumtime`<br>然后手动执行<br>`pip install onnxruntime-gpu`
|
||||
|
||||
|
||||
@ -2,14 +2,124 @@
|
||||
|
||||
# 带带弟弟OCR通用验证码识别SDK免费开源版
|
||||
|
||||
# 2021/12/24重大更新,ddddocr现在支持通用目标检测啦
|
||||
# 今天ddddocr又更新啦!
|
||||
当前版本为1.3.1
|
||||
|
||||
想必很多做验证码的新手,一定头疼碰到点选类型的图像,做样本费时费力,神经网络不会写,训练设备太昂贵,模型效果又不好。
|
||||
|
||||
市场上常见的点选类验证码图片如下图所示
|
||||
|
||||
|
||||
## 交流群(找对象,在苏州,dd群主)
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
## 环境要求
|
||||

|
||||
|
||||

|
||||
|
||||
那么今天,他来了,ddddocr带着重磅更新大摇大摆的走来了。
|
||||
# 简介
|
||||
ddddocr是由sml2h3开发的专为验证码厂商进行对自家新版本验证码难易强度进行验证的一个python库,其由作者与kerlomz共同合作完成,通过大批量生成随机数据后进行深度网络训练,本身并非针对任何一家验证码厂商而制作,本库使用效果完全靠玄学,可能可以识别,可能不能识别。
|
||||
|
||||
ddddocr奉行着开箱即用、最简依赖的理念,尽量减少用户的配置和使用成本,希望给每一位测试者带来舒适的体验
|
||||
|
||||
项目地址: [点我传送](https://github.com/sml2h3/ddddocr)
|
||||
|
||||
# 更新说明
|
||||
|
||||
本次更新其实分为两部分,其中有一部分是在1.2.0版本就已经更新了,但是在这里还是有必要提一下的。
|
||||
|
||||
## 第一部分 OCR识别部分
|
||||
|
||||
在1.2.0开始,ddddocr的识别部分进行了一次beta更新,主要更新在于网络结构主体的升级,其训练数据并没有发生过多的改变,所以理论上在识别结果上,原先可能识别效果的很好的图形在1.2.0上有一小部分概率会有一定程度的下降,也有可能原本识别不好的图形在1.2.0之后效果却变得特别好。
|
||||
测试代码:
|
||||
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
|
||||
ocr = ddddocr.DdddOcr()
|
||||
|
||||
with open("test.jpg", 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
res = ocr.classification(image)
|
||||
print(res)
|
||||
```
|
||||
由于事实上确实在一些图片上老版本的模型识别效果比新模型好,特地这次更新把老模型也加入进去了,通过在初始化ddddocr的时候使用old参数即可快速切换老模型
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
|
||||
ocr = ddddocr.DdddOcr(old=True)
|
||||
|
||||
with open("test.jpg", 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
res = ocr.classification(image)
|
||||
print(res)
|
||||
```
|
||||
|
||||
OCR部分应该已经有很多人做了测试,在这里就放一部分网友的测试图片。
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||
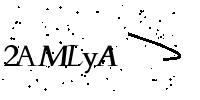
|
||||

|
||||

|
||||

|
||||

|
||||
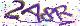
|
||||

|
||||

|
||||
等等更多图片等你测试哟~
|
||||
|
||||
## 第二部分 目标检测部分
|
||||
在本次1.3.0的更新中,目标检测部分隆重登场!
|
||||
目标检测部分同样也是由大量随机合成数据训练而成,对于现在已有的点选验证码图片或者未知的验证码图片都有可能具备一定的识别能力,适用于文字点选和图标点选。
|
||||
简单来说,对于点选类的验证码,可以快速的检测出图片上的文字或者图标。
|
||||
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
import cv2
|
||||
|
||||
det = ddddocr.DdddOcr(det=True)
|
||||
|
||||
with open("test.jpg", 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
poses = det.detection(image)
|
||||
print(poses)
|
||||
|
||||
im = cv2.imread("test.jpg")
|
||||
|
||||
for box in poses:
|
||||
x1, y1, x2, y2 = box
|
||||
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
|
||||
|
||||
cv2.imwrite("result.jpg", im)
|
||||
|
||||
```
|
||||
|
||||
举些例子:
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||

|
||||

|
||||

|
||||
|
||||
以上只是目前我能找到的点选验证码图片,做了一个简单的测试。
|
||||
|
||||
# 安装
|
||||
|
||||
## 环境支持
|
||||
|
||||
`python <= 3.9`
|
||||
|
||||
@ -17,69 +127,15 @@
|
||||
|
||||
暂时不支持Macbook M1(X),M1(X)用户需要自己编译onnxruntime才可以使用
|
||||
|
||||
## 调用方法
|
||||
## 安装命令
|
||||
|
||||
`pip install ddddocr`
|
||||
|
||||
### 1、文字识别模式
|
||||
以上命令将自动安装符合自己电脑环境的最新ddddocr
|
||||
|
||||
```python
|
||||
import ddddocr
|
||||
ocr = ddddocr.DdddOcr()
|
||||
with open('test.png', 'rb') as f:
|
||||
img_bytes = f.read()
|
||||
res = ocr.classification(img_bytes=img_bytes)
|
||||
print(res)
|
||||
```
|
||||
或者传入图片 base64 编码值(不包含图片头)
|
||||
```python
|
||||
import ddddocr
|
||||
ocr = ddddocr.DdddOcr()
|
||||
img_base64 = 'img_base64' # 示例
|
||||
res = ocr.classification(img_base64=img_base64)
|
||||
print(res)
|
||||
```
|
||||
# 交流群 (加我好友拉你进群)
|
||||
|
||||
### 2、目标检测模式
|
||||
```python
|
||||
import ddddocr
|
||||
det = ddddocr.DdddOcr(det=True)
|
||||

|
||||
|
||||
with open('test.jpg', 'rb') as f:
|
||||
img_bytes = f.read()
|
||||
|
||||
res = det.detection(img_bytes)
|
||||
print(res)
|
||||
```
|
||||
|
||||
### 3、参数说明
|
||||
|
||||
`DdddOcr 接受三个参数`
|
||||
|
||||
| 参数名 | 默认值 | 说明 |
|
||||
| ---- | ---- | ---- |
|
||||
| det | False | Bool 默认为识别文字模式,为True则开启目标检测模式 |
|
||||
| use_gpu | False | Bool 是否使用gpu进行推理,如果该值为False则device_id不生效 |
|
||||
| device_id | 0 | int cuda设备号,目前仅支持单张显卡 |
|
||||
|
||||
`classification`
|
||||
|
||||
必须det参数为False后才可使用
|
||||
|
||||
| 参数名 | 默认值 | 说明 |
|
||||
| ---- | ---- | ---- |
|
||||
| img_bytes | None | bytes 图片的bytes格式 |
|
||||
| img_base64 | None | 图片的 base64 编码值(不包含图片头) |
|
||||
|
||||
`detection`
|
||||
|
||||
必须det参数为False后才可使用
|
||||
|
||||
| 参数名 | 默认值 | 说明 |
|
||||
| ---- | ---- | ---- |
|
||||
| img_bytes | None | bytes 图片的bytes格式 |
|
||||
| img_base64 | None | 图片的 base64 编码值(不包含图片头) |
|
||||
|
||||
> 说明,当 `img_bytes` 和 `img_base64` 都存在时,优先使用 `img_bytes`
|
||||
|
||||
> 如果使用GPU,需要自行安装cuda和cudnn,并在安装完ddddocr时执行 <br>`pip uninstall onnxrumtime`<br>然后手动执行<br>`pip install onnxruntime-gpu`
|
||||
|
||||
|
||||
1948
ddddocr/__init__.py
1948
ddddocr/__init__.py
File diff suppressed because it is too large
Load Diff
BIN
ddddocr/common_old.onnx
Normal file
BIN
ddddocr/common_old.onnx
Normal file
Binary file not shown.
2
setup.py
2
setup.py
@ -14,7 +14,7 @@ with open("README.md", "r", encoding="utf-8") as fh:
|
||||
|
||||
setup(
|
||||
name="ddddocr",
|
||||
version="1.3.0",
|
||||
version="1.3.1",
|
||||
author="sml2h3",
|
||||
description="带带弟弟OCR",
|
||||
long_description=long_description,
|
||||
|
||||
Loading…
Reference in New Issue
Block a user